Kelsey Hightower on Platforms in the Agentic Era and the Launch of Massdriver v2
Watch On-Demand
devopsplatform engineeringdeveloper platformcloud infrastructure
DevOps is Bullshit
A Critique of How We've Fooled Ourselves for Years.
Update: A follow up article was posted on the Microsoft Blog .
DevOps started as a well-intentioned set of practices and culture.
Over the years, it has devolved into an unholy beast of division and tunnel vision. Why did we stop dreaming bigger? What happened to tearing down silos, increasing engineering velocity, and adding value? Remember? The things DevOps was supposed to do?
But the reality is, outside of FAANG and the most well-funded companies, your team is probably doing one of the following:
1. You’ve got a DevOps team.
Congrats, that’s not DevOps. I’d wager most of what they are doing is using Terraform and YAML to do menial tasks for the engineering team.
Need a database? File a ticket with DevOps.
Need an IAM role? File a ticket with DevOps.
Before long, your massive team of engineers has fully saturated your understaffed “DevOps” team’s backlog.
This approach does not scale.
2. You’re doing DevOps, but it feels like shit.
DevOps, the free-for-all where each engineer does the necessary ops to do their job.
Best practices? We’ll invent them along the way!
Secure? I’m too busy increasing conversion rates!
Naming conventions? Nah. NAH. nah-prod. PROD-NAH. PRODUCTION-NAH
Cost management? Deleting unused cloud resources? Nope, we’ve got AWS credits to burn! 🔥
The problem is most engineers don’t want to do operations work.
They want to build the product. They want to add tangible value. But organizations will force this upon them, and engineers will either work with what they’ve already got, guess their way through some new cloud service, or the DevOps tasks will slowly become the responsibility of a few individuals that become the “DevOps” team.
The worst part of this scenario is that deadlines rule, and product stakeholders don’t see ops.
When was the last time you saw a product manager high-five the ops person and say, ‘fast fucking autoscaler!’?
Slowly your team feels the malleable nature of DevOps stagnate into rigid infrastructure as teams stop making the hard operations decisions and just bend their software around what they have.
In the end, all infrastructure eventually becomes a platform - how easy is yours to change?
Operations is a Commodity; Let’s Act Like It
I’ve been on the operations side of engineering for a long time. I’ve been developing in Ruby since Rails 1.0. Before that, I wrote some of the trashiest PHP the world has seen. I had the opportunity to migrate from a data center to AWS EC2 when it was launched in 2006. As I’ve become more experienced in operations, I was “pigeonholed” into the “DevOps” role.
To date, I’ve deployed over 200 production-grade Kubernetes clusters across a handful of companies.
Want to know a secret?
I’ve copied and pasted the same damn Terraform modules for every single one. My job felt like a scam, but companies pay me for my expertise in Kubernetes, not for writing Terraform. I had built a copy-paste-driven, single-user platform-as-a-service and no one cared so long as nothing was broken.
You’ve made it this far, so I’m just going to say it:
The companies building “DevOps” teams are going in the right direction, but they need to be moving away from infrastructure configuration management and towards platform engineering and enabling developer self-service.
The knowledge silos are good. The silos are a feature, not a bug.
Expertise is a good thing.
DevOps is bullshit.
How “Ops” Breaks the Loop
Continuous advancement through teamwork, efficiency in communication, elevated morale, leaving the door open to suggestions for betterment… sign me up, right?
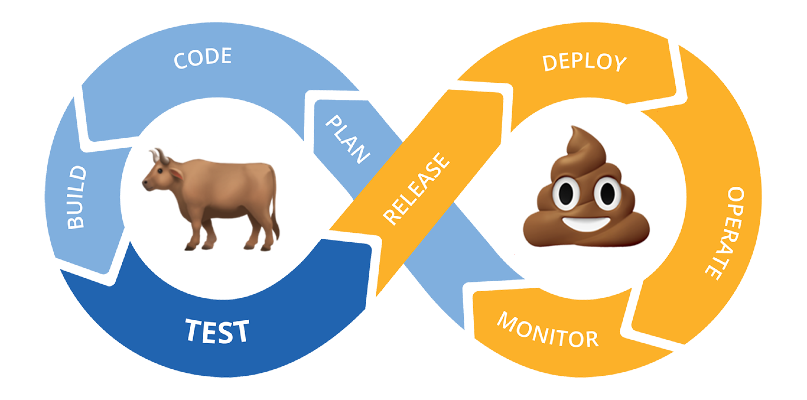
This model worked when the cloud was simple. It made sense, even. Back when we had a few virtual machines, maybe an S3 bucket and a couple of queues, this loop was achievable. What threw a wrench in everything was the growing complexity of our systems, the operational burden of those systems, and compliance. For many organizations, operations teams inevitably become DevOps gatekeepers at every phase of the loop.
Planning
Planning today requires knowledge and trade-offs of cloud services. As the cloud has gotten more complex, teams are left with a few options: work with what they’ve got or sync with ops to see what their backlog looks like.
Organizations that have invested in platform engineering have either a golden path already identified or enable teams to research and develop new golden paths rapidly. This flexibility is key to a great platform. We aren’t building “golden roads”, they are paths. Golden paths should provide direction and guardrails but be adaptable when the business needs change.
Coding
Coding is becoming more and more of a hodge-podge of cloud APIs. This is a good thing! We should want to write and run less code.
Do you know what’s worse than waiting through an ops backlog during the planning phase? Missing your deadline and working late because you’re waiting for someone on the ops team to update IAM policies and create KMS keys because you didn’t realize the SNS Topics were in a different region than your SQS Queues.
A great internal developer platform has conventions in place to handle the small tedious bits of the cloud, like IAM and KMS, that take the most amount of time to address. They focus on an engineer’s intentions, not making engineers worry over implementation details.
Build, test, release, and deploy
Ah yes, CI/CD. The fuzzy boundary between development and production. These phases are so fraught with bullshit that they’ve become meme-worthy:

But it’s not an “ops problem”, it’s an entire organization problem. I’m convinced that the CI/CD phase is the root of where frustration and division grow between operations and engineering teams.
Take this fairly common example:
In production, we are running in containers, but developing in the container is too slow, so the team leans towards asdf and a README full of stuff to copy, paste, and pray. During a sprint, an engineer adds convert (ImageMagick) to the mix to support manipulating images and forgets to update the Dockerfile, and then production goes down.
This is where trust between developers and operations begins to erode.
Internal developer platforms should allow an engineer to run their application where they want, how they want. Lambda and Docker, sure. K8s + Buildpacks, sure. VMs and a tarball, sure.
Unfortunately, many of the platforms today force developers to run on Kubernetes. A great developer platform meets engineers where they are. It should be flexible in architecture but opinionated in self-service.
Operate and Monitor
The final stages of this “perfect” loop model are arguably where Ops should be. That’d be great, except now we’ve got SREs to cover that. Huh.
If the “DevOps” team ships a Postgres RDS instance it will run fine forever, that is until an application starts using it. All of a sudden a cascade of N+1s hit, the CPU spikes, and queries grind to a halt. Who is woken up? And why does this always happen at 2 AM? In this scenario, there is nothing for operations personnel to do, yet here they are.
Do you still think DevOps is doing what it’s supposed to do?
The expertise that operations and SRE teams have is critical to developing secure, scalable systems, but the old idea of “DevOps” and the hurdles our industry has turned it into is holding us back.
It’s Time to Bury DevOps
I’ve spent a good portion of the last two years talking to teams about their cloud infrastructure and DevOps processes/culture. I’ve heard the above rant in some form from team after team. What’s more concerning about the state of DevOps today are some of the other things I’ve heard…
Show of hands—how many people in your organization think CI/CD is DevOps?
Show of hands—how many people in your organization think they don’t need DevOps because they run serverless?
Show of hands—how many of you think the above two interpretations are a problem?
To most, the term “DevOps” has completely lost its meaning.
If you’re really really doing DevOps, do you think reinventing all of that commodity is really worth your engineering team’s time? Is that a good investment for the business?
“You build it, you run it.” Pffffft. More like: You build it, but it takes longer than your sprint estimate, and you cut corners on the ops bit that doesn’t fit your “definition of done.”
Knowledge silos and expertise are two sides of the same coin. From full stack engineering to DevOps practitioner, our industry loves to pretend everyone can do everything. We’re an industry of hobbyists. We love to tinker. I don’t know if we are fooling ourselves or if the industry has been exploiting our hobby-driven nature, but it’s time for DevOps to get thrown out of an airlock.
The growing zeitgeist is that “platform engineering is the future.” And given that I co-founded a product in the space, I sure hope so! Unfortunately, organizations can’t get there by expecting the “DevOps” team to do it. I’m sorry, but copy/pasting some Terraform modules between your git repos is a terrible “platform.” Your engineers don’t want to deal with it, and inevitably your ops team will be on the hook for supporting it. Hell, even HashiCorp is jumping on the “no code” provisioning train for their “please contact sales” plan. Huh, seems like all these companies with enterprise bucks are struggling too.
So how does the average organization get to the promised land of Platform Engineering?
Simple, just hire some more frontend and backend engineers to develop a great internal PaaS with all the golden paths your operations team is architecting while you are trying to build your actual product that runs on top of it.
Obviously easier said than done.
To get there, many organizations will need a reality check.
For every operations person without software development skills, there are FORTY engineers without cloud operations skills. If you are going to build an internal platform, you’ll need experts with overlapping experience in both fields working together.
You are also going to need a shitload of time and budget. This isn’t a hackathon project. It isn’t the pet project of the new CTO with a wild hair up their ass to plant their flag on the business. You can give it a cute “skunkworks” name to show everyone you have access to Wikipedia too, but building an internal platform is a startup within your primary business. Building an internal development platform is like changing the tires and engine of a car while it is hurtling toward a cliff.
Stay agile.
Migrate an auxiliary service to it quickly.
Get feedback from your engineering customers.
Yeah. ENGINEERING CUSTOMERS. They aren’t your team anymore. They are your business’s second set of customers, but if these customers aren’t buying it, you end up with morale problems, engineers pining for “the old way,” a boatload of debt, and a bunch of wasted time and effort.
Chin up! You or the new CTO’s next team can get it done.
What’s in a Great Internal Developer Platform?
If you are planning to build a platform, there are five core components that are required, but in our experience, there are a few more attributes that make for a great platform.
Extendable with open-source tooling. Teams and workloads are different and will have different golden paths. If an IDP has one opinionated way to run your workload, it is no better than a PaaS. An abstraction over Kubernetes is not enough. IDPs must work for all workload types, whether containerized, serverless, or virtualized.
Anti-Lock-In, you should be able to walk away from a bad build-or-buy decision without risking production or having an arduous migration process.
Security, compliance, and guardrails must be built in. Without them, you are not enabling self-service, you are enabling disservice. The fastest way to derail self-service is a CISO worrying about a breach. A simple web form or YAML abstraction over an AWS or GCP API is not enough. Expertise in practices and security must be included.
Powerful building blocks to increase engineering velocity. We have an industry-wide shortage of expertise in the cloud space, a great IDP should have safe, dependable building blocks for designing cloud services quickly.
Enable experimentation through flexibility and extensibility. If you have to reach for another tool or platform to see how your app would work in a serverless container or with a different Pub/Sub system, you are going to receive pushback from your stakeholders in your IDP. IDPs must enable experimentation so the right decisions can be made for our applications.
Ephemeral environments for applications and infrastructure must be supported. Our applications are becoming so heavily dependent on cloud services. If you can’t provision dependencies like buckets, queues, or databases, when you open a pull request, then are you really getting a close approximation to production?
Configurable alerting and monitoring for provisioned infrastructure and applications with good defaults. If engineers can deploy their own resources, they must be monitored without requiring an extra tool to configure. Otherwise, the likelihood that those resources have alerts configured will decrease significantly.
Platform engineering is possible, and it is the future. Our systems are getting more complicated and higher scale earlier as more and more parts of the world get online. We’re creating great new engineers daily out of boot camps, but we aren’t excelling in operational maturity as an industry. We have a lot of data to protect. We are stewards of personal information. Customers assume we have a fiduciary responsibility, but we mostly act like hobbyists. We need to make sure “platform engineering” is not the next bullshit buzzword.


